ICLR 2026 Benchmark
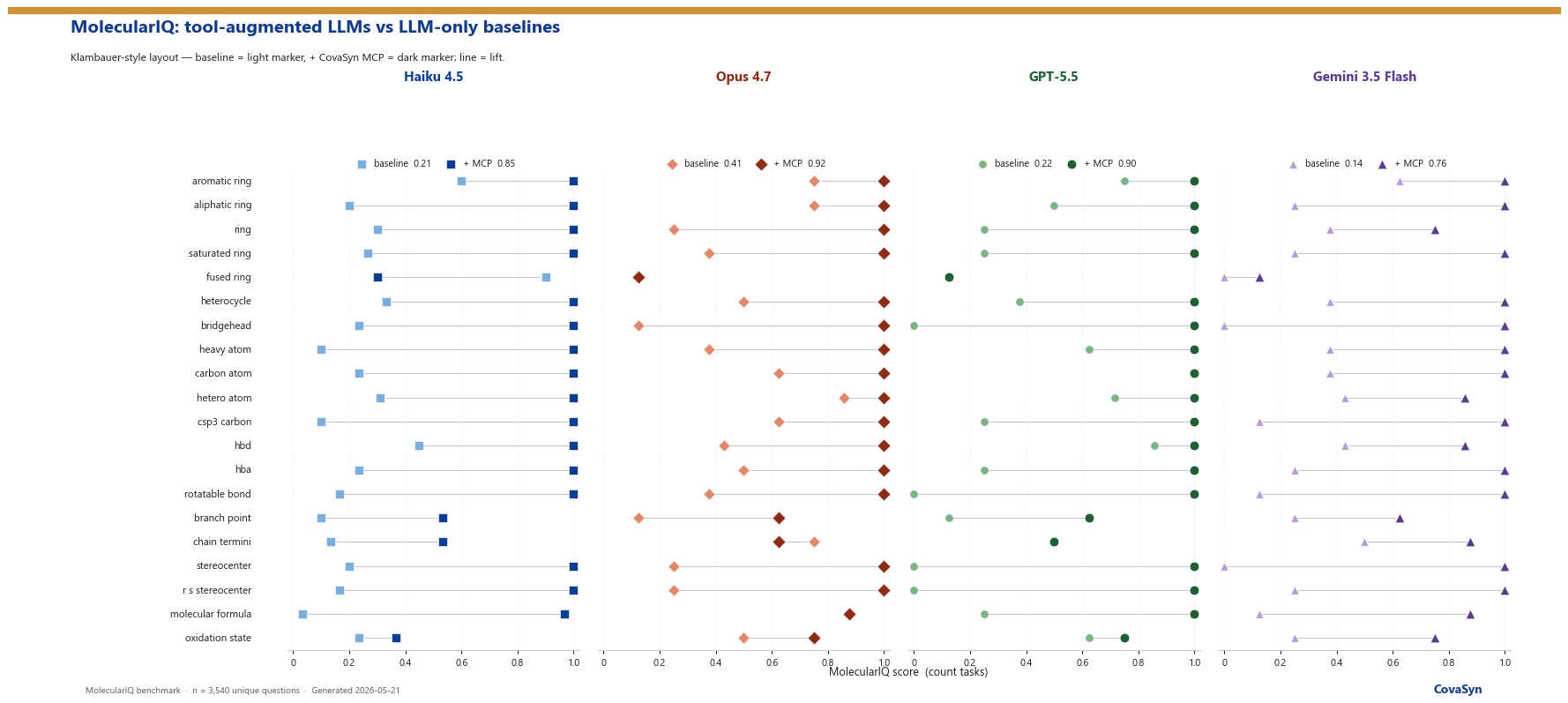
Auf dem peer-reviewed MolecularIQ-Benchmark erreichen vier Frontier-LLMs 14 bis 41 Prozent bei chemischer Strukturanalyse. Mit CovaSyn-MCP-Anbindung steigen die gleichen Modelle auf 76 bis 92 Prozent. Drei der vier landen bei 85 bis 92 %, das günstigste Modell (Gemini 3.5 Flash) bei 76 %. Hier sind die Zahlen, und was sie nicht zeigen.
Top-Line-Zahlen
| Modell | Baseline | + CovaSyn MCP | Δ | Lift |
|---|---|---|---|---|
| Claude Haiku 4.5 | 21,18 % | 85,38 % | +64,20 pp | 4,03× |
| Claude Opus 4.7 | 40,75 % | 91,51 % | +50,76 pp | 2,25× |
| OpenAI GPT-5.5 | 22,29 % | 89,92 % | +67,63 pp | 4,03× |
| Gemini 3.5 Flash | 13,68 % | 75,66 % | +61,98 pp | 5,53× |
Was das in Kosten bedeutet
Frontier-Modelle sind teuer. Mit CovaSyn lässt sich oft das günstigere Modell verwenden, ohne Genauigkeit aufzugeben.
| Konfiguration | Genauigkeit | $/Frage | Latenz |
|---|---|---|---|
| Haiku 4.5 baseline | 21,18 % | 0,00069 $ | 2,1 s |
| Haiku 4.5 + CovaSyn MCP | 85,38 % | 0,00781 $ | 5,8 s |
| Opus 4.7 baseline | 40,75 % | 0,02529 $ | 5,1 s |
| Opus 4.7 + CovaSyn MCP | 91,51 % | 0,12536 $ | 7,4 s |
| GPT-5.5 baseline | 22,29 % | 0,02750 $ | 7,9 s |
| GPT-5.5 + CovaSyn MCP | 89,92 % | 0,03005 $ | 9,4 s |
| Gemini 3.5 Flash baseline | 13,68 % | 0,00940 $ | 5,5 s |
| Gemini 3.5 Flash + CovaSyn MCP | 75,66 % | 0,02170 $ | 10,8 s |
Die scharfe Aussage:
Haiku 4.5 + CovaSyn ist der Kosten-Effizienz-Sweetspot: 2,1× die Genauigkeit von Opus 4.7 baseline bei 32 % der Kosten, und 16× günstiger als Opus 4.7 + CovaSyn bei nur 6 pp weniger Genauigkeit. Gemini 3.5 Flash + CovaSyn liefert den größten relativen Lift (5,53× von 13,7 % auf 75,7 %) bei rund 2,3× Baseline-Kosten und 2× Baseline-Latenz, die richtige Option für Teams, die Gemini bereits im Stack haben.




Wo CovaSyn am stärksten hebelt
Mean-Accuracy-Lift über 8 Frage-Kategorien (Durchschnitt über Haiku 4.5, Opus 4.7 und GPT-5.5; Gemini 3.5 Flash analog, Detail-Daten kommen mit dem nächsten Snapshot):
| Kategorie | Baseline | + CovaSyn MCP | Δ |
|---|---|---|---|
| Scaffold & Fragments | 18,0 % | 86,5 % | +68,4 pp |
| Rings & Topology | 29,4 % | 93,2 % | +63,8 pp |
| Bonds & Chains | 17,6 % | 80,9 % | +63,3 pp |
| Multi-Feature Questions | 27,3 % | 88,4 % | +61,1 pp |
| Atom & Formula Counts | 38,7 % | 98,3 % | +59,7 pp |
| Stereochemistry | 28,7 % | 86,0 % | +57,4 pp |
| Electronics & H-Bonds | 31,2 % | 81,5 % | +50,3 pp |






Methodik
Benchmark
MolecularIQ von Bartmann et al., ICLR 2026 (arXiv:2601.15279). 3.540 Aufgaben, 65 Merkmale, drei Komplexitätsstufen. Dataset öffentlich auf HuggingFace.
Modelle
Claude Haiku 4.5, Claude Opus 4.7, OpenAI GPT-5.5 und Gemini 3.5 Flash. Jeweils mit und ohne CovaSyn-MCP-Anbindung.
Verifikation
Symbolisch, ohne LLM-Richter. Score nur bei voller Übereinstimmung mit der Ground Truth.
Tools
Fünf Chemie-Primitive aus der CovaBasicChem-Suite. Cheminformatik-Operationen, deterministisch, validiert.
Volumen
12.540 Modell-Antworten insgesamt. Haiku auf dem vollen Test-Split, Opus, GPT-5.5 und Gemini auf einer stratifizierten Stichprobe (910 Fragen je Modell).
Wo wir noch besser werden
Keine 100 % Trefferquote, und genau das wollen wir auch nicht verheimlichen. Hier siehst du, wie sich die verbleibenden Fehler verteilen und an welchen Stellen du für deine eigene Validierung genauer hinschauen solltest.
| Kategorie | Haiku + MCP | Opus + MCP | GPT-5.5 + MCP | Gemini + MCP |
|---|---|---|---|---|
| Korrekt | 73,2 % | 83,0 % | 83,6 % | 72,3 % |
| Tool-Ergebnis verworfen | 21,6 % | 14,5 % | 10,9 % | 6,9 % |
| Tool-Wert nicht passend | 4,8 % | 2,2 % | 1,4 % | 0,7 % |
| Formatfehler | 0,2 % | 0,2 % | 4,1 % | 20,1 % |
Der Großteil der verbleibenden Lücke entsteht zwischen Tool und Modell, nicht im Tool selbst. Wir adressieren das laufend.
Quellenangabe
Bartmann C., Schimunek J., Ielanskyi M., Seidl P., Klambauer G., Luukkonen S. (2026). MolecularIQ: Characterizing Chemical Reasoning Capabilities Through Symbolic Verification on Molecular Graphs. ICLR 2026 (Poster, Pavilion 4 · P4-#5202, 24 Apr 2026), arXiv:2601.15279. Code: github.com/ml-jku/moleculariq. Dataset: huggingface.co/datasets/ml-jku/moleculariq-v0.0. Daten-Snapshot: 2026-05-17.
Tiefer einsteigen
Ausführliche Analyse mit Methodik, Implikationen und FAQ
Etwa 12 Minuten Lesezeit. Hintergrund zur Modell-Auswahl, Cost-Pareto im Detail, GxP-Implikationen, häufige Fragen. →
Selbst testen
Die Tools, die diesen Lift produzieren, stehen in jedem CovaSyn-Account zur Verfügung. Auch im Free-Tier mit 100 Credits pro Woche.