ICLR-2026-Benchmark im Detail
Die Kurzversion zeigt die Zahlen. Diese Seite ist für alle, die Methodik, Hintergrund, Implikationen und offene Fragen vertieft wissen wollen. Lesezeit etwa 12 Minuten.
Warum ein externer Benchmark
Vendor-eigene Benchmarks sind in der Pharma-Welt zu Recht mit Misstrauen behaftet. Jeder Anbieter, der seine eigenen Tools testet, hat einen Anreiz, sich gut darzustellen. Wir wollten diesen Anreiz aus dem Spiel nehmen und haben uns deshalb für einen unabhängigen, peer-reviewed Benchmark entschieden, den wir nicht designed haben und auf dessen Aufgabenwahl wir keinen Einfluss hatten.
Die Wahl fiel auf MolecularIQ aus dem Klambauer-Lab am Institut für Machine Learning der JKU Linz. Das Lab ist eine der etablierten Adressen für KI-in-der-Chemie-Forschung, der Benchmark wurde auf der ICLR 2026 angenommen, und das Dataset liegt vollständig öffentlich auf HuggingFace.
Methodik
MolecularIQ enthält 13.170 Aufgaben über acht Splits. Für unsere Auswertung haben wir den Test-Split mit 3.540 Aufgaben verwendet, eingegrenzt auf jene Frage-Typen, die symbolisch verifizierbar sind. Symbolische Verifikation bedeutet, dass die Antwort entweder exakt mit der Ground Truth übereinstimmt oder als falsch zählt. Es gibt keinen LLM-Richter, keine Teilpunkte, keinen Interpretationsspielraum. Diese Strenge sorgt dafür, dass das Ergebnis robust gegen Cherry-Picking ist.
Wir haben vier Frontier-Modelle getestet: Claude Haiku 4.5, Claude Opus 4.7, OpenAI GPT-5.5 und Google Gemini 3.5 Flash. Jedes Modell wurde in zwei Konfigurationen durchlaufen, einmal ohne externe Tools und einmal mit CovaSyn-MCP-Anbindung. Insgesamt sind dabei 12.540 Modell-Antworten entstanden. Auf der vollen Stichprobe für Haiku 4.5, auf einer stratifizierten Teilstichprobe für Opus 4.7, GPT-5.5 und Gemini 3.5 Flash, um die Kosten in einem vernünftigen Rahmen zu halten.
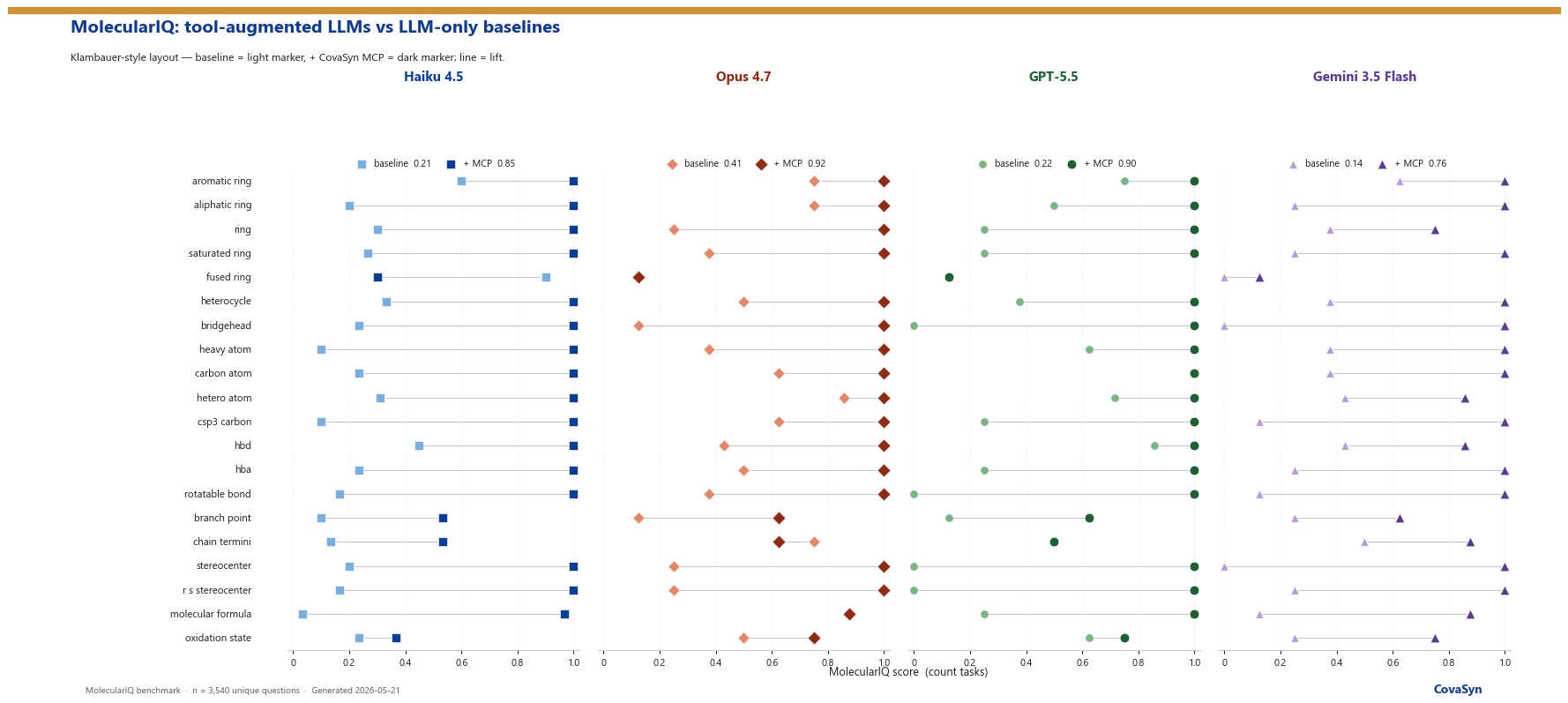
Die Ergebnisse im Überblick
Haiku 4.5 ohne Tools erreicht 21,18 Prozent. Mit CovaSyn-MCP-Anbindung springt das Modell auf 85,38 Prozent, ein Faktor von 4. Opus 4.7 ohne Tools liegt bei 40,75 Prozent, mit MCP bei 91,51 Prozent. GPT-5.5 macht den gleichen Sprung wie Haiku, von 22,29 auf 89,92 Prozent. Gemini 3.5 Flash startet am niedrigsten mit 13,68 Prozent baseline und springt auf 75,66 Prozent mit MCP, der absolut größte Lift im Test mit 5,53-fachem Faktor.
Vier Modelle, drei verschiedene Anbieter, gleiche Richtung. Das ist die wichtigste Aussage. Der Effekt der MCP-Anbindung ist nicht an ein spezifisches Modell gebunden, sondern reproduzierbar quer durch die Frontier-Landschaft. Wer heute mit Claude arbeitet, kann morgen auf GPT-5.5 oder Gemini wechseln, und der Effekt bleibt.
Die Cost-Story
Genauigkeit ist die eine Hälfte der Geschichte. Kosten pro Frage sind die andere. Wer in Pharma-Workflows skaliert, denkt nicht in einzelnen Tokens, sondern in tausenden oder zehntausenden Tool-Calls pro Woche.
Opus 4.7 ohne MCP kostet pro Frage 0,02529 US-Dollar bei 40,75 Prozent Genauigkeit. Opus 4.7 mit MCP-Anbindung kostet 0,12536 US-Dollar bei 91,51 Prozent. Haiku 4.5 mit MCP kostet 0,00781 US-Dollar bei 85,38 Prozent. Gemini 3.5 Flash mit MCP kostet 0,02170 US-Dollar bei 75,66 Prozent (rund 2,3× der Gemini-Baseline-Kosten von 0,00940 US-Dollar). Diese Konfigurationen sind die direkte Konkurrenz zur ersten.
Konkret: Haiku 4.5 mit MCP liefert mehr als das Doppelte an Genauigkeit, die Opus baseline erreicht, und kostet rund ein Drittel. Verglichen mit Opus plus MCP gibt Haiku sechs Prozentpunkte Genauigkeit ab, kostet aber nur etwa ein Sechzehntel. Gemini 3.5 Flash mit MCP schlägt Opus baseline um über 30 Prozentpunkte bei rund 86 Prozent der Opus-Baseline-Kosten, die richtige Wahl, wenn Gemini bereits im Stack steht. Wer pro Monat zehntausend Tool-Calls absetzt, zahlt mit der Opus-Plus-MCP-Variante 1.250 Dollar, mit Haiku-Plus-MCP rund 78 Dollar, mit Gemini-Plus-MCP rund 217 Dollar.




Per-Kategorie-Auswertung
Der Benchmark teilt seine Aufgaben in acht Kategorien. Über alle vier Modelle gemittelt sind die größten Sprünge in den Bereichen Scaffold und Fragmente (von 15,5 auf 83,9 Prozent), Ringe und Topologie (26,7 auf 89,3 Prozent), Bindungen und Ketten (16,1 auf 77,4 Prozent), Mehrfach-Bedingungen (24,7 auf 84,5 Prozent), Atom- und Formel-Zählungen (35,5 auf 94,3 Prozent), Stereochemie (27,1 auf 80,5 Prozent), Elektronik und H-Brücken (28,4 auf 76,3 Prozent).
Das sind die Bausteine der täglichen Med-Chem-Arbeit. Ein Scaffold-Hop muss in Sekunden durchgerechnet sein, eine Ring-Analyse darf nicht ins Halluzinieren kippen, ein Mehrfach-Constraint wie "alle Branch-Points innerhalb zweier Bindungen zu einem Halogen" muss exakt aufgelöst werden. Genau hier liegen die größten Hebel.




Wo die verbleibende Lücke sitzt
Keine 100 Prozent Trefferquote bedeutet, dass es eine verbleibende Lücke gibt. Wir haben sie nicht versteckt, sondern publiziert. Die Lücke verteilt sich auf drei Kategorien.
In rund 11 bis 22 Prozent der Fälle ignoriert das Modell ein korrektes Tool-Ergebnis und produziert eine eigene Antwort. Dieses Verhalten ist modell-spezifisch, nicht tool-spezifisch. Es lässt sich durch Prompt-Strukturierung deutlich reduzieren, ist aber nicht trivial vollständig zu eliminieren.
In 1 bis 5 Prozent der Fälle passt der Tool-Wert nicht zur Frage. Das sind echte Fehler im Workflow, meist auf Edge-Cases bei komplexer Stereochemie oder ungewöhnlichen Strukturen. Diese Fälle adressieren wir laufend.
Unter 5 Prozent fallen Format-Fehler, in denen der LLM-Output nicht parseable ist. Diese Klasse ist klein, technisch leicht zu fangen und für regulierte Workflows unproblematisch, weil sie über Output-Validation auffällt.
Implikationen für Pharma R&D
Erstens, das Modell ist nicht mehr automatisch das Bottleneck. Wer heute pro Chemie-Query 0,03 Dollar zahlt, kann mit gleicher oder besserer Genauigkeit auf 0,008 Dollar runtergehen. Das ändert die Kostenrechnung für Med-Chem-Workflows substantiell.
Zweitens, der Lift ist modell-unabhängig. Wer eine MCP-Schicht aufbaut, ist nicht an Anthropic, OpenAI oder Google gebunden. Sobald das nächste Frontier-Modell kommt, lässt sich die MCP-Schicht direkt davor hängen und der Effekt überträgt sich.
Drittens, die Lücke ist transparent. Für GxP-Validierungs-Argumentationen ist eine ehrliche Fehlerverteilung wertvoller als ein bestpoliert klingendes Vendor-Versprechen. Ein QA-Team kann aus den publizierten Fehlerklassen direkt Risk-Assessment-Tabellen und Acceptance-Criteria ableiten.
Häufige Fragen
Was ist der MolecularIQ-Benchmark?
Ein 2026 vom Klambauer-Lab an der JKU Linz publizierter Benchmark, der die Fähigkeit von Sprachmodellen zur strukturierten chemischen Analyse misst. 3.540 Aufgaben, 65 Merkmale, drei Komplexitätsstufen, symbolische Verifikation ohne LLM-Richter.
Warum springt die Genauigkeit so stark mit CovaSyn-MCP?
Sprachmodelle raten bei strukturellen Chemie-Aufgaben wie Atomzählen oder Scaffold-Extraktion oft, weil sie keinen deterministischen Mechanismus haben. CovaSyn liefert per Tool-Call exakte Antworten aus cheminformatischen Bibliotheken, die der LLM in seine Antwort einbaut.
Wie kann Haiku 4.5 mit CovaSyn günstiger sein als Opus 4.7 ohne?
Haiku 4.5 ist je Token rund 15 Mal günstiger als Opus 4.7. Wenn der MCP-Layer dem kleineren Modell die strukturelle Korrektheit liefert, bleibt vom Modell nur das Format- und Reasoning-Layer übrig, das Haiku gut bewältigt. Resultat: 85 Prozent Genauigkeit bei 0,008 Dollar pro Frage.
Lässt sich das Ergebnis reproduzieren?
Ja. Das Dataset liegt öffentlich auf HuggingFace, der Benchmark-Code ist auf GitHub, die Modelle sind über offizielle APIs zugänglich, und ein CovaSyn-Free-Tier-Account erlaubt den MCP-Zugriff. Eine vollständige Replikation ist in einem Nachmittag machbar.
Warum hat Gemini 3.5 Flash den niedrigsten Score bei höchstem Lift?
Gemini 3.5 Flash startet mit 13,68 Prozent baseline am niedrigsten der vier Modelle, weil das Modell auf Geschwindigkeit und Kosten optimiert ist, nicht auf strukturelle Chemie. Genau deshalb ist der relative Lift mit 5,53× am größten: die MCP-Schicht liefert die strukturelle Korrektheit, die im baseline-Modell fehlt. Bei 0,02170 USD pro Frage (rund 2,3× Baseline-Kosten) schlägt Gemini-Plus-MCP Opus baseline um über 30 Prozentpunkte, bei deutlich niedrigeren Kosten als Opus + MCP.
Was ist mit den anderen CovaSyn-Suiten?
Die hier publizierten Zahlen kommen aus einer der acht Suiten. Die anderen sieben werden gerade gegen passende Datensätze gebencht. Sobald die Ergebnisse vorliegen, kommen sie auf dieselbe Seite. Volle Methodik, volle Verteilung, kein Cherry-Picking.
Quellenangabe
Bartmann C., Schimunek J., Ielanskyi M., Seidl P., Klambauer G., Luukkonen S. (2026). MolecularIQ: Characterizing Chemical Reasoning Capabilities Through Symbolic Verification on Molecular Graphs. ICLR 2026 (Poster). arXiv:2601.15279. Code: github.com/ml-jku/moleculariq. Dataset: huggingface.co/datasets/ml-jku/moleculariq-v0.0. Daten-Snapshot: 2026-05-17.
Selbst nachvollziehen
Die Anbindung ist in jedem CovaSyn-Account aktiv. 100 Credits pro Woche im Free-Tier reichen für eine eigene kleine Reproduktion.