ICLR 2026 Benchmark in Depth
The short version shows the numbers. This page is for readers who want methodology, background, implications, and open questions in depth. About 12 minutes of reading.
Why an external benchmark
Vendor-run benchmarks in the pharma world are rightly met with skepticism. Anyone testing their own tools has an incentive to look good. We wanted to take that incentive off the table and chose an independent, peer-reviewed benchmark that we did not design and over which we had no influence on task selection.
The pick was MolecularIQ from the Klambauer Lab at JKU Linz's Institute for Machine Learning. The lab is one of the established names in AI-for-chemistry research, the benchmark was accepted at ICLR 2026, and the dataset is fully public on HuggingFace.
Methodology
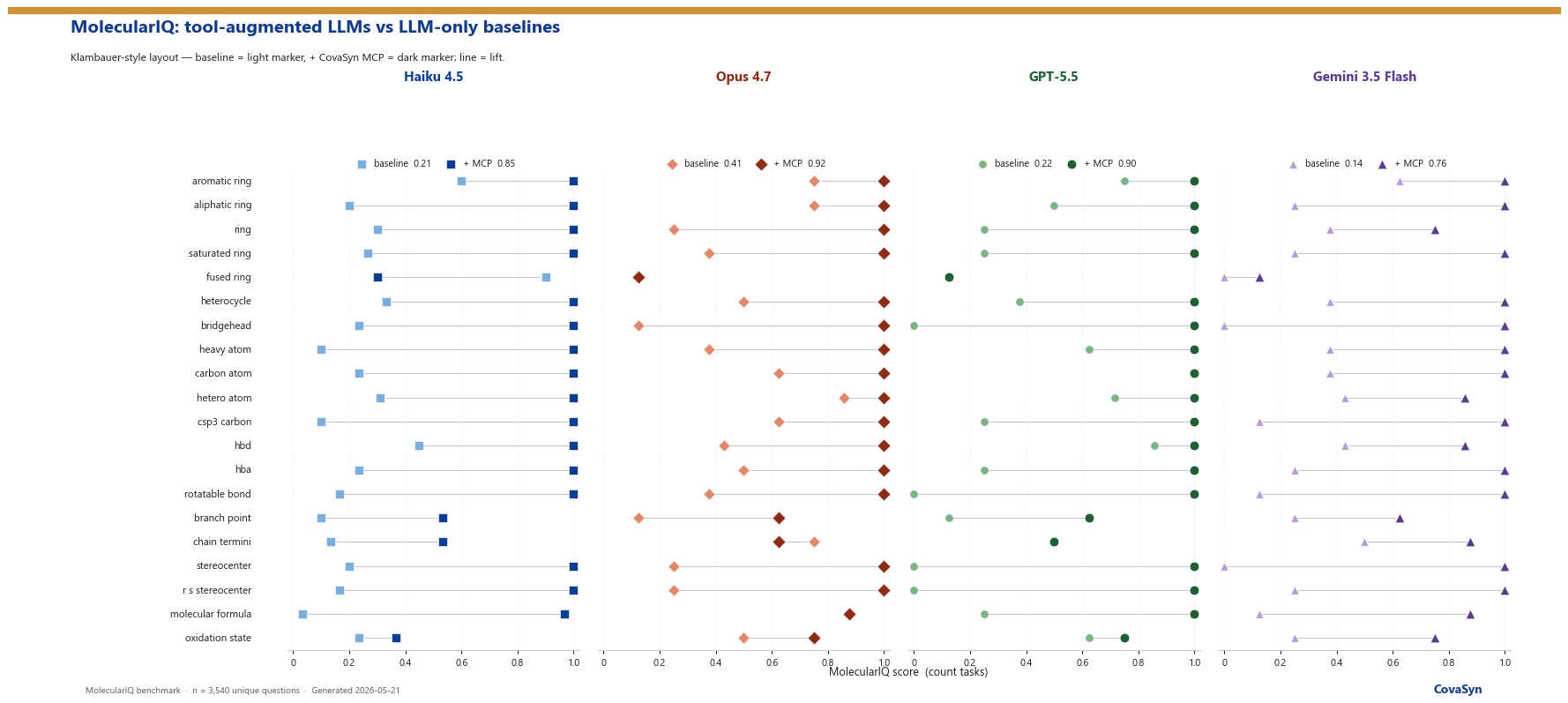
MolecularIQ contains 13,170 tasks across eight splits. For our evaluation we used the test split with 3,540 tasks, restricted to the question types that are symbolically verifiable. Symbolic verification means the answer either matches ground truth exactly or counts as wrong. No LLM judge, no partial credit, no interpretation. That strictness makes the result robust against cherry-picking.
We tested four frontier models: Claude Haiku 4.5, Claude Opus 4.7, OpenAI GPT-5.5, and Google Gemini 3.5 Flash. Each model ran in two configurations, once without external tools and once with CovaSyn MCP attached. In total that produced 12,540 model responses. The full sample for Haiku 4.5, a stratified subsample for Opus 4.7, GPT-5.5, and Gemini 3.5 Flash to keep the cost manageable.
Results at a glance
Haiku 4.5 without tools reaches 21.18 percent. With CovaSyn MCP attached the model jumps to 85.38 percent, a factor of 4. Opus 4.7 without tools lands at 40.75 percent, with MCP at 91.51 percent. GPT-5.5 mirrors the Haiku jump, from 22.29 to 89.92 percent. Gemini 3.5 Flash starts lowest at 13.68 percent baseline and jumps to 75.66 percent with MCP, the largest absolute lift in the test at a 5.53x factor.
Four models, three different providers, same direction. That is the most important takeaway. The MCP effect is not tied to a specific model but reproducible across the frontier. Anyone working with Claude today can switch to GPT-5.5 or Gemini tomorrow, and the effect carries over.
The cost story
Accuracy is one half. Cost per question is the other. Pharma teams scaling AI think not in tokens but in thousands or tens of thousands of tool calls per week.
Opus 4.7 without MCP costs 0.02529 US dollars per question at 40.75 percent accuracy. Opus 4.7 with MCP attached costs 0.12536 dollars at 91.51 percent. Haiku 4.5 with MCP costs 0.00781 dollars at 85.38 percent. Gemini 3.5 Flash with MCP costs 0.02170 dollars at 75.66 percent (roughly 2.3× the Gemini baseline cost of 0.00940 dollars). Those configurations are the direct competition to the first one.
Concretely: Haiku 4.5 with MCP delivers more than twice the accuracy of Opus baseline at roughly a third of the cost. Against Opus plus MCP it gives up six percentage points of accuracy but costs about one-sixteenth. Gemini 3.5 Flash with MCP beats Opus baseline by over 30 percentage points at roughly 86 percent of the Opus baseline cost, the right pick when Gemini is already in the stack. The order of magnitude matters. Ten thousand tool calls per month on Opus plus MCP cost 1,250 dollars, on Haiku plus MCP roughly 78 dollars, on Gemini plus MCP roughly 217 dollars.




Per-category breakdown
The benchmark splits tasks into eight categories. Averaged over the four models, the biggest jumps sit in scaffold and fragments (from 15.5 to 83.9 percent), rings and topology (26.7 to 89.3), bonds and chains (16.1 to 77.4), multi-feature constraints (24.7 to 84.5), atom and formula counts (35.5 to 94.3), stereochemistry (27.1 to 80.5), electronics and H-bonds (28.4 to 76.3).
Those are the building blocks of daily med-chem work. A scaffold hop has to run in seconds, a ring analysis cannot drift into hallucination, a multi-constraint query like "all branch points within two bonds of a halogen" needs to resolve exactly. That is where the biggest leverage sits.




Where the remaining gap sits
Not hitting 100 percent means there is a remaining gap. We did not hide it, we published it. The gap distributes across three categories.
In roughly 11 to 22 percent of cases the model ignores a correct tool result and produces its own answer. This behaviour is model-specific rather than tool-specific. Prompt structuring reduces it noticeably but does not trivially eliminate it.
In 1 to 5 percent of cases the tool value does not fit the question. These are real workflow errors, mostly edge cases with complex stereochemistry or unusual structures. We address those on a rolling basis.
Below 5 percent fall format errors where the LLM output is not parseable. This class is small, technically easy to catch, and unproblematic for regulated workflows because output validation surfaces it.
Implications for pharma R&D
First, the model is no longer automatically the bottleneck. Teams paying 0.03 dollars per chemistry query can move to 0.008 dollars at equal or better accuracy. That meaningfully changes the math for med-chem workflows.
Second, the lift is model-independent. Teams that build an MCP layer are not locked to Anthropic, OpenAI, or Google. When the next frontier model arrives, the MCP layer goes directly in front of it and the effect carries over.
Third, the gap is transparent. For GxP validation arguments an honest error distribution is worth more than a polished vendor promise. A QA team can derive risk-assessment tables and acceptance criteria directly from the published failure classes.
FAQ
What is the MolecularIQ benchmark?
A benchmark published in 2026 by the Klambauer Lab at JKU Linz that measures language models' ability to perform structured chemistry analysis. 3,540 tasks, 65 features, three complexity bins, symbolic verification without LLM judges.
Why does accuracy jump so much with CovaSyn MCP?
Language models frequently guess on structural chemistry tasks like atom counts or scaffold extraction because they lack a deterministic mechanism. CovaSyn delivers exact answers via tool calls to cheminformatics libraries, which the LLM then surfaces in its response.
How can Haiku 4.5 with CovaSyn be cheaper than Opus 4.7 without?
Haiku 4.5 is roughly 15 times cheaper per token than Opus 4.7. When the MCP layer delivers structural correctness to the smaller model, only the formatting and reasoning layer remains, which Haiku handles well. Result: 85 percent accuracy at 0.008 dollars per question.
Can the result be reproduced?
Yes. The dataset is public on HuggingFace, the benchmark code is on GitHub, the models are accessible via official APIs, and a CovaSyn free tier provides MCP access. A full replication is achievable in an afternoon.
Why does Gemini 3.5 Flash post the lowest score but the largest lift?
Gemini 3.5 Flash starts at 13.68 percent baseline, the lowest of the four models, because it is optimized for speed and cost rather than structural chemistry. That is exactly why its relative lift at 5.53x is the largest: the MCP layer provides the structural correctness the baseline model lacks. At 0.02170 USD per question (roughly 2.3× its baseline cost), Gemini-plus-MCP still beats Opus baseline by over 30 percentage points, at meaningfully lower cost than Opus + MCP.
What about the other CovaSyn suites?
The numbers published here come from one of eight suites. The other seven are currently being benchmarked against matching datasets. Once results land, they will appear on the same page. Full methodology, full distribution, no cherry-picking.
Citation
Bartmann C., Schimunek J., Ielanskyi M., Seidl P., Klambauer G., Luukkonen S. (2026). MolecularIQ: Characterizing Chemical Reasoning Capabilities Through Symbolic Verification on Molecular Graphs. ICLR 2026 (poster). arXiv:2601.15279. Code: github.com/ml-jku/moleculariq. Dataset: huggingface.co/datasets/ml-jku/moleculariq-v0.0. Data snapshot: 2026-05-17.
See it for yourself
The integration is available in every CovaSyn account. The 100 weekly free-tier credits are enough for a small reproduction of your own.